
Output / Research Journal
Intelligence and its vital flaws
Note 7 from the research journal by Nicklas Lundblad: As we design artificial agents (or delegates) one of the interesting challenges that we will have to sort out is to figure out how to decide mechanisms that ensure that the agent does not act in certain circumstances.
Note 7.
Just as we would ideally want to have artificial intelligences that can state clearly when they are not sure, or do not know something, we need to have agents that can decide not to act or abstain from acting in different ways.
In a recent paper the authors address this critical gap in AI systems that make personalized decisions (like medical treatments or targeted advertising). Current algorithms always force a decision between two options even when the evidence is weak or uncertain. In high-stakes situations like healthcare, this can be risky - sometimes the best choice is to defer to a human expert or stick with a safe default option rather than making a potentially harmful guess. Or do nothing at all!
The researchers introduce a framework where AI policies can output a third option: "abstain". When the algorithm abstains, it receives a small reward bonus on top of what it would get from randomly choosing between the two treatments. The key technical contribution is a two-stage algorithm: first, it identifies a set of near-optimal strategies from observational data; then, it creates an "abstention class" by having policies abstain precisely where they disagree with each other (signaling uncertainty). The authors prove that this approach achieves fast learning rates without requiring strong assumptions that prior methods needed.
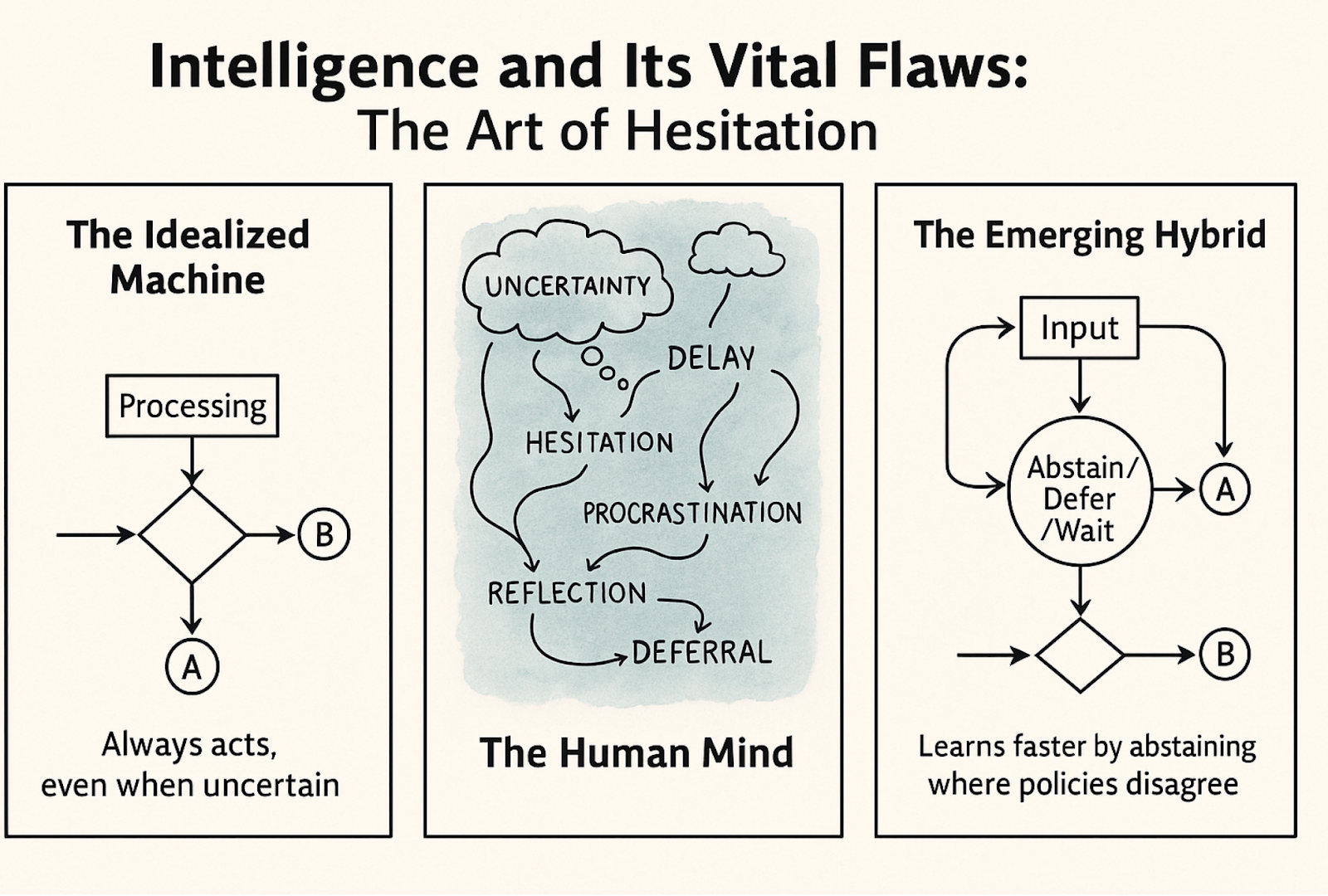
Beyond the core abstraction framework, the paper shows this approach solves several other important problems. It enables learning good strategies even when the treatment effect isn't clearly separated from zero (relaxing common "margin" assumptions). It provides a natural way to safely improve upon baseline policies - by abstaining in uncertain regions and deferring to the baseline, you can ensure you don't make things worse.
You can - in other words - hesitate.
This, the ability to build hesitation mechanisms, represents just a small fraction of similar adaptations that we will have to figure out as we build AI with agency. What at a first glance may look as weaknesses in human decision making - that we hesitate, doubt ourselves, procrastinate and second guess ourselves and others - are all behavior that at some point in evolution was selected for, or at the very least not selected against (some behavior can be the product of drift, of course).
That we are now trying to build these functions in artificial intelligence may well also be a sign that we are discovering something interesting about intelligence – and it may even be a sign that the model of intelligence that we have been able to produce with large language models may actually not be human at all. We have built something that at a surface level behaves in ways that feel human, but when we look at all the “small” behaviors that we exhibit as human beings, well, they are often missing.
Maybe we have been caught in a trap here – we have focused on the main case (where intelligence can solve a problem) and not looked at how intelligence fails, hesitates, doubts, waits – all the small behaviors that are so easy to dismiss as flaws. But our intelligence hinges on these flaws, and is made stronger for it – and the fact that we are now bolting them on in various solutions and fixes - that we are adding them as kludges - could be a first indicator that maybe the difference between the current models of intelligence and our own intelligence are larger than we may have thought.

Take procrastination (a flaw this human is prone to!): is that just a weakness or is there a point in having some extra time, waiting until a thought is fully formed, drifting and mindwandering? Maybe the time we procrastinate is time when we subconsciously process and explore different aspects of a problem? Ok, sure, this may be self-deception at its worst - after all, there are maladaptive human behaviors as well - but it is worth looking at the flaws in our intelligence and re-examine if they are flaws at all.
And here an interesting research project can be thought up: what would it mean to build an intelligence that naturally - without added kludges - hesitates, doubts and waits before deciding? What does the architecture look like that allows for all of those behavior to emerge naturally?
My suspicion here is that human intelligence is a patchwork of evolutionarily favored functions, carefully balanced across a deep time, whereas the AI we are currently building is a construct that has not been shaped by those same evolutionary forces. Some reject this distinction and say that intelligence is intelligence no matter how it was arrived at - but it seems to me that it is logically consistent to argue the opposite: that the reference class for AI is not human intelligence and other evolved functions, but the class of built, brittle things that we have constructed as tools.
I am not sure I believe that, and I do think there is a risk that we fall into the trap of using evolution to make the human mind mystical - but in designing agents that hesitate and doubt, I think we are at least catching a glimpse of something important: a difference that may well be more salient than previously thought.


