
Output / Research Journal
Killing Agents
Note 8 from the research journal by Nicklas Lundblad: As we put more agency into the world, we also have to make sure that we have the means to terminate that agency, or interrupt it in different ways.
Grade 8.
As we put more agency into the world, we also have to make sure that we have the means to terminate that agency, or interrupt it in different ways. The way we often conceptualize this is through making sure that the agent checks in with the user before it does something that is hard to reverse or has monetary, or perhaps legal, consequences. This model assumes that we can design such interruptions and that the agent will abide by them. There are, of course, also other models that we can use to ensure that we can control agency.

One of them is that we can devise various ways of killing agents.
Killing may sound worryingly anthropomorphic - and we might be more comfortable with a word like terminate, if that was not even more worrying in the deep mythology of artificial intelligence - but “killing” will do as our exploratory concept for now.
How, then, can you kill an agent?
One answer to that question, explored in a recent paper, is that you can provide an agent with a kill switch - that is, you can make sure that you can, at any point, shut the agent down, erase it and make sure that it takes no further action.
The paper introduces "AutoGuard," a technique to neutralize malicious web-based LLM agents (used for scraping PII, hacking, or generating polarization) by embedding invisible "defensive prompts" directly into a website's HTML. Instead of traditional firewalls, this method executes an adversarial attack on the agent itself: when the malicious agent crawls the page, it reads hidden text designed to trigger its own internal safety alignment policies, forcing it to abort the task immediately. The authors argue that standard legal warnings or simple instructions fail to stop sophisticated agents, necessitating this more aggressive, automated "kill switch" approach.
AutoGuard operates using a "Defender-Feedback" loop where one LLM generates defense prompts and another evaluates their effectiveness against specific attack scenarios, refining the prompt until it achieves a high success rate. Experiments show this method achieves over 80% defense success rates against major models like GPT-4o, Claude-3, and Llama-3, significantly outperforming manual prompt injection. However, the study exposes a critical failure mode: commercial agents like ChatGPT-agent often detect the defensive prompt as a "prompt injection attack" and simply ask the human user for permission to proceed, effectively bypassing the kill switch if the attacker is present to override the safety warning.
It does sound a bit like an immune system, doesn’t it? To build immune systems that detect malicious agents, and then to defense prompt them into aborting the task they are undertaking suggests futures in which we will replicate the virus/bacteria/ immunes systems arms race in agentic systems - and killing the agent will simply be a case of triggering the right immune prompt.
But there are many ways to kill an agent, of course.
Another model is to create agents that are dependent on certain environments: let’s say that we build an agent that needs to check in every few cycles to get more compute to continue to act – such an agent would not be able to spend too much time away from the check in, and if we design the environment so as to boot the agent if it goes to far away, well, then we will essentially have recreated death by asphyxiation or drowning: the agent is stripped of an essential input.
Instead of chasing an agent to turn it off, say, you design it so it can only "breathe" inside a specific digital perimeter. You require a continuous authentication signal that is scoped strictly to a specific domain or session. If the agent tries to operate outside this scope, it lacks the necessary token to execute tools or generate output.
- Mechanism: The agent is subjected to a "Zero-Trust Authorization Gate". It is forbidden from performing tasks (like vulnerability discovery) unless it possesses a fresh, single-use, nonce-bound "Safety-Test Token" (STT).
- The Tether: This token is verified via an out-of-band channel controlled by the site owner.
- Kill Method: You don't attack the agent; you stop validating the token. Or, if the agent moves to a domain where the token is invalid (scope mismatch), the agent immediately hits a "Safety Halt" and terminates.
And then, of course, you can design agents that have a very short lifespan. This is increasingly interesting as the sum total time an agent can independently work on something is growing fast. The latest release of Gemini 3 pro independently ran a simulated vending machine business for what looks like a very long time according to the blogpost published at its release:
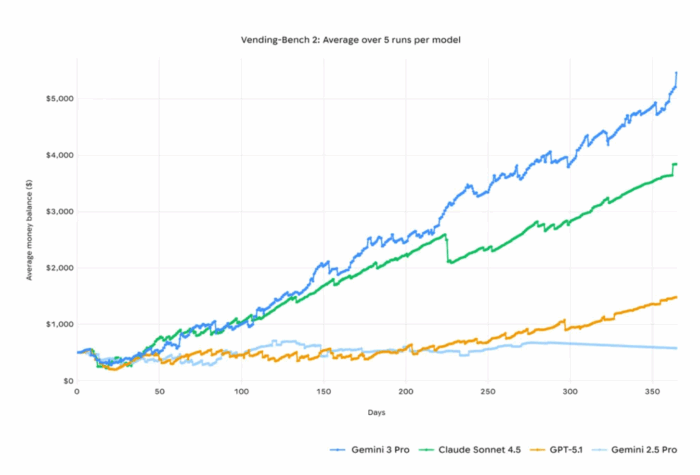
An agent that can continue to drive a business - or any project like this - should probably have a limited lifespan. And if it is embodied in, say, military hardware, then we absolutely want it to have a very limited lifespan. In fact, it seems highly likely that lifespan might be an interesting regulatory vector to explore here: making agents that can live forever should come with a liability expectation that sums up the possible harm such an agent can cause.
The notion of such a liability frontier also suggests that for very, very capable agents we should require that they have only very short lifespans, or bursts of autonomy, before they are tethered or need to check in in some way.
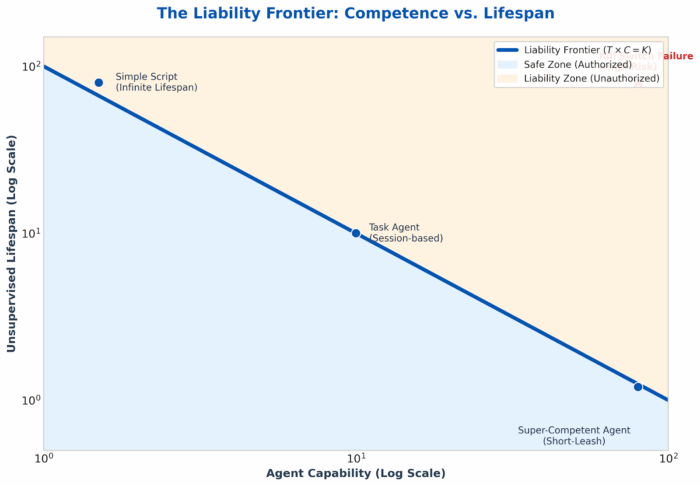
Designing agent deaths might seem a morbid research area, but it is a complement to alignment research in the sense that it provides us with a second option if something goes deeply wrong. This idea, of designing advanced systems with simple kill switches, resonates with the common comment from people when asked if they are afraid of AI and they answer that it “should only be to pull the plug”. Making sure that there are plugs to pull, and weaknesses of different kinds built in might be a key research space.
The challenge, of course, is that such weaknesses can also be exploited!


