
Output / Forschungstagebuch
Agenten töten
Notiz 8 aus dem Forschungstagebuch von Nicklas Lundblad: Wenn wir Agenten mehr Handlungsfähigkeit verleihen, müssen wir auch sicherstellen, dass wir über die Mittel verfügen, diese Handlungsfähigkeit zu beenden oder auf verschiedene Weise zu unterbrechen.
Notiz 8.
Wenn wir Agenten mehr Handlungsmacht verleihen, müssen wir auch sicherstellen, dass wir über die Mittel verfügen, diese Handlungsautonomie zu beenden oder auf verschiedene Weise zu unterbrechen. Oft stellen wir uns das so vor, dass der Agent sich beim Nutzer vergewissert, bevor er etwas tut, das schwer rückgängig zu machen ist oder finanzielle oder vielleicht rechtliche Konsequenzen hat. Dieses Modell geht davon aus, dass wir solche Unterbrechungen gestalten können und dass der Agent sich daran hält. Es gibt natürlich auch andere Modelle, mit denen wir sicherstellen können, dass wir die Handlungsfähigkeit kontrollieren können.

Ein Grund dafür ist, dass wir verschiedene Methoden entwickeln können, um Agenten zu töten.
„Töten“ mag beunruhigend anthropomorph klingen – und wir würden uns vielleicht mit einem Begriff wie „beenden“ wohler fühlen, wäre dieser in der tiefgreifenden Mythologie der künstlichen Intelligenz nicht noch beunruhigender –, aber „Töten“ reicht vorerst als unser exploratives Konzept aus.
Wie kann man also einen Agenten töten?
Eine Antwort auf diese Frage, die in einer aktuellen Veröffentlichung untersucht wurde, lautet, dass man einem Agenten einen Kill-Schalter zur Verfügung stellen kann – das heißt, man kann sicherstellen, dass man den Agenten jederzeit abschalten, löschen und dafür sorgen kann, dass er keine weiteren Aktionen ausführt.
Die Studie stellt „AutoGuard“ vor, eine Technik zur Neutralisierung bösartiger webbasierter LLM-Agenten (die zum Scraping personenbezogener Daten, zum Hacken oder zur Erzeugung von Polarisierung eingesetzt werden), indem unsichtbare „defensive Prompts“ direkt in den HTML-Code einer Website eingebettet werden. Anstelle herkömmlicher Firewalls führt diese Methode einen gegnerischen Angriff auf den Agenten selbst durch: Wenn der bösartige Agent die Seite crawlt, liest er versteckten Text, der darauf ausgelegt ist, seine eigenen internen Sicherheitsrichtlinien auszulösen, wodurch er gezwungen wird, die Aufgabe sofort abzubrechen. Die Autoren argumentieren, dass standardmäßige rechtliche Warnhinweise oder einfache Anweisungen nicht ausreichen, um ausgefeilte Agenten zu stoppen, was diesen aggressiveren, automatisierten „Kill-Switch“-Ansatz erforderlich macht.
AutoGuard arbeitet mit einem „Defender-Feedback“-Kreislauf, bei dem ein LLM Verteidigungs-Prompts generiert und ein anderes deren Wirksamkeit gegen bestimmte Angriffsszenarien bewertet, wobei der Prompt so lange verfeinert wird, bis eine hohe Erfolgsquote erreicht wird. Experimente zeigen, dass diese Methode gegen führende Modelle wie GPT-4o, Claude-3 und Llama-3 Verteidigungserfolgsraten von über 80 % erzielt und damit die manuelle Prompt-Injektion deutlich übertrifft. Die Studie deckt jedoch einen kritischen Fehlermodus auf: Kommerzielle Agenten wie ChatGPT-Agent erkennen die Verteidigungsaufforderung oft als „Prompt-Injection-Angriff“ und bitten den menschlichen Nutzer einfach um Erlaubnis, fortzufahren, wodurch der Kill-Switch effektiv umgangen wird, wenn der Angreifer anwesend ist, um die Sicherheitswarnung zu überschreiben.
Das klingt ein bisschen wie ein Immunsystem, nicht wahr? Immunsysteme zu entwickeln, die bösartige Agenten erkennen, und sie dann durch defensive Prompts dazu zu bringen, die von ihnen ausgeführte Aufgabe abzubrechen, deutet auf eine Zukunft hin, in der wir das Wettrüsten zwischen Viren, Bakterien und Immunsystemen in agentenbasierten Systemen nachbilden werden – und das Ausschalten des Agenten wird einfach nur eine Frage der Auslösung des richtigen Immun-Prompts sein.
Aber es gibt natürlich viele Möglichkeiten, einen Agenten auszuschalten.
Aber es gibt natürlich viele Möglichkeiten, einen Agenten zu töten.
Ein weiteres Modell besteht darin, Agenten zu erstellen, die von bestimmten Umgebungen abhängig sind: Nehmen wir an, wir entwickeln einen Agenten, der sich alle paar Zyklen melden muss, um weitere Rechenleistung zu erhalten und weiter agieren zu können – ein solcher Agent könnte sich nicht allzu lange von der Meldepflicht entfernen, und wenn wir die Umgebung so gestalten, dass der Agent neu gestartet wird, sobald er sich zu weit entfernt, dann haben wir im Grunde den Tod durch Ersticken oder Ertrinken nachgebildet: Dem Agenten wird eine wesentliche Eingabe entzogen.
Anstatt einem Agenten hinterherzujagen, um ihn abzuschalten, gestalten Sie ihn so, dass er nur innerhalb eines bestimmten digitalen Perimeters „atmen“ kann. Sie verlangen ein kontinuierliches Authentifizierungssignal, das streng auf eine bestimmte Domäne oder Sitzung beschränkt ist. Wenn der Agent versucht, außerhalb dieses Bereichs zu operieren, fehlt ihm das erforderliche Token, um Tools auszuführen oder Ausgaben zu generieren.
- Mechanismus: Der Agent wird einem „Zero-Trust-Autorisierungsgate“ unterzogen. Es ist ihm untersagt, Aufgaben (wie die Erkennung von Schwachstellen) auszuführen, es sei denn, er verfügt über ein frisches, einmalig verwendbares, an einen Nonce gebundenes „Safety-Test-Token“ (STT).
- Die Verbindung: Dieses Token wird über einen vom Website-Betreiber kontrollierten Out-of-Band-Kanal verifiziert.
- Kill-Methode: Man greift den Agenten nicht an, sondern stellt die Validierung des Tokens ein. Oder wenn der Agent in eine Domäne wechselt, in der das Token ungültig ist (Bereichsinkongruenz), stößt der Agent sofort auf einen „Safety Halt“ und wird beendet.
Und dann kann man natürlich auch Agenten entwickeln, die nur eine sehr kurze Lebensdauer haben. Dies wird immer interessanter, da die Gesamtzeit, die ein Agent selbstständig an einer Aufgabe arbeiten kann, rapide zunimmt. Die neueste Version von Gemini 3 Pro hat laut einem Blogbeitrag, der anlässlich der Veröffentlichung erschien, ein simuliertes Automaten-Geschäft über einen Zeitraum betrieben, der sehr lang erscheint:
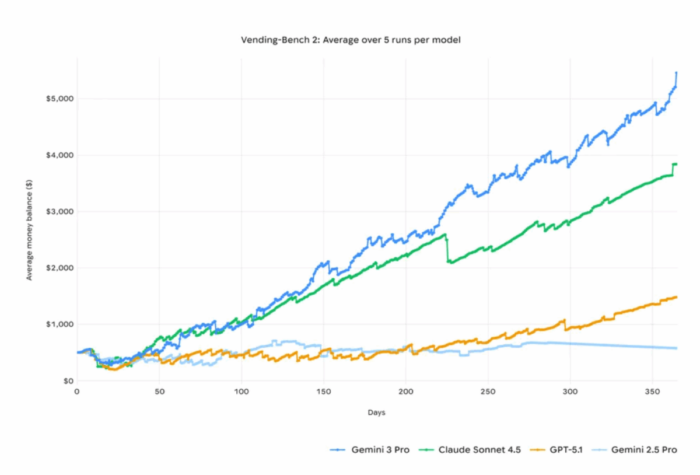
Ein Agent, der ein Unternehmen – oder ein ähnliches Projekt – weiterführen kann, sollte wahrscheinlich eine begrenzte Lebensdauer haben. Und wenn er beispielsweise in militärischer Hardware verkörpert ist, dann wollen wir unbedingt, dass er eine sehr begrenzte Lebensdauer hat. Tatsächlich scheint es sehr wahrscheinlich, dass die Lebensdauer hier ein interessanter Regulierungsansatz sein könnte: Die Entwicklung von Agenten, die ewig leben können, sollte mit einer Haftungserwartung einhergehen, die den möglichen Schaden, den ein solcher Agent verursachen kann, berücksichtigt.
Das Konzept einer solchen Haftungsgrenze legt auch nahe, dass wir von sehr, sehr fähigen Agenten verlangen sollten, dass sie nur eine sehr kurze Lebensdauer oder kurze Phasen der Autonomie haben, bevor sie wieder angebunden werden oder sich auf irgendeine Weise melden müssen.
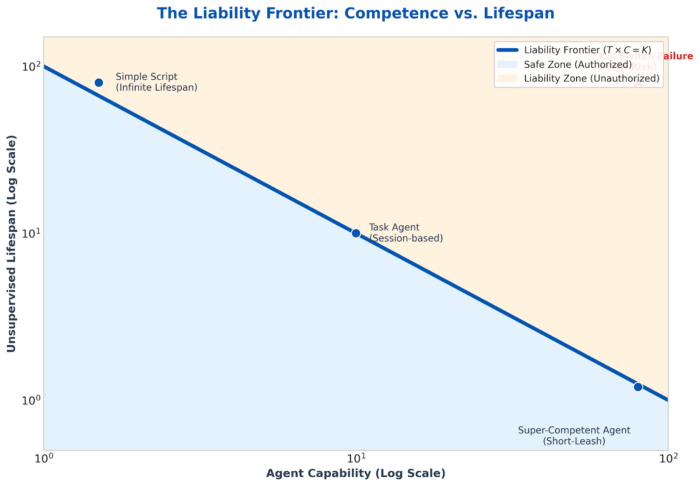
Das Entwerfen von Mechanismen zum Ausschalten von Agenten mag wie ein makaberes Forschungsgebiet erscheinen, doch es ergänzt die Alignment-Forschung insofern, als es uns eine zweite Option bietet, falls etwas grundlegend schiefgeht. Diese Idee, fortschrittliche Systeme mit einfachen Abschaltmechanismen zu entwerfen, deckt sich mit der häufigen Reaktion von Menschen, die auf die Frage, ob sie Angst vor KI hätten, antworten, dass es „nur darum gehen sollte, den Stecker zu ziehen“. Sicherzustellen, dass es Stecker gibt, die man ziehen kann, und Schwachstellen verschiedener Art einzubauen, könnte ein wichtiger Forschungsbereich sein.
Die Herausforderung besteht natürlich darin, dass solche Schwachstellen auch ausgenutzt werden können!


